이번 글에서는 Docker Compose를 사용하여 PostgreSQL Replication 환경을 구축하고, PgCat을 통한 Connection Pooling을 구현하는 방법을 알아보겠습니다.
1. 프로젝트 구조
프로젝트는 다음과 같은 파일들로 구성되어 있습니다:
- docker-compose.yml: 컨테이너 구성 정의
- .env: 환경 변수 설정
- config/pgcat.simple.toml: PgCat 설정 파일
2. 환경 변수 설정 (.env)
환경 변수를 통해 데이터베이스 접속 정보와 포트 설정을 관리합니다:
# PostgreSQL 기본 설정
POSTGRESQL_USERNAME=postgres
POSTGRESQL_DATABASE=postgres
POSTGRESQL_PASSWORD=mysecretpassword
# 복제 설정
POSTGRESQL_REPLICATION_USER=repl_user
POSTGRESQL_REPLICATION_PASSWORD=repl_password
# 포트 설정
PGCAT_PORT=6432
PG1_PORT=5433
PG2_PORT=5434
PG3_PORT=5435
3. PostgreSQL Replication 구성
Master 노드 (pg1)
- Primary 데이터베이스 서버로 동작
- 읽기/쓰기 작업 모두 수행
- 복제 모드: master
POSTGRESQL_REPLICATION_MODE: master
POSTGRESQL_REPLICATION_USER: ${POSTGRESQL_REPLICATION_USER}
POSTGRESQL_REPLICATION_PASSWORD: ${POSTGRESQL_REPLICATION_PASSWORD}
Replica 노드 (pg2, pg3)
- Secondary 데이터베이스 서버로 동작
- 읽기 전용 작업 수행
- 복제 모드: slave
- Master 노드의 데이터를 실시간으로 복제
POSTGRESQL_REPLICATION_MODE: slave
POSTGRESQL_MASTER_HOST: pg1
POSTGRESQL_MASTER_PORT_NUMBER: 5432
4. PgCat을 통한 Connection Pooling
PgCat은 PostgreSQL용 고성능 커넥션 풀러로, 다음과 같은 기능을 제공합니다:
주요 설정
- Transaction 단위의 커넥션 풀링
- 읽기/쓰기 쿼리 분리
- 로드 밸런싱
- 상태 모니터링 (Prometheus)
[pools.postgres]
pool_mode = "transaction"
query_parser_enabled = true
query_parser_read_write_splitting = true
서버 구성
- Primary (pg1): 쓰기 작업 처리
- Replica (pg2, pg3): 읽기 작업 처리
servers = [
[ "pg1", 5432, "primary" ],
[ "pg2", 5432, "replica" ],
[ "pg3", 5432, "replica" ]
]
5. 시스템 아키텍처
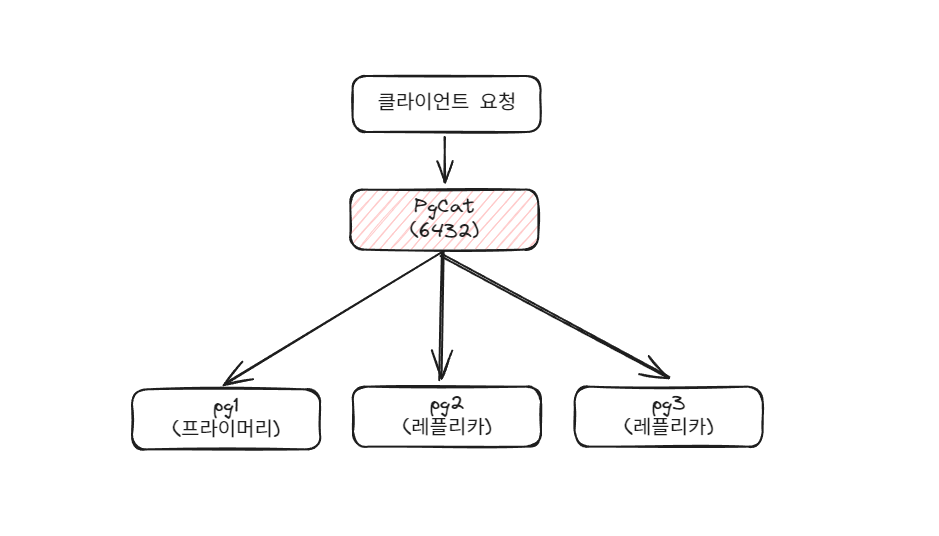
- 클라이언트는 PgCat(6432)로 연결
- PgCat이 쿼리 유형에 따라 적절한 서버로 라우팅
- 쓰기 쿼리 → Primary (pg1)
- 읽기 쿼리 → Replica (pg2, pg3)
6. 장점
-
고가용성
- Master 노드 장애 시에도 Replica를 통한 읽기 작업 가능
- 데이터 복제를 통한 데이터 안정성 확보
-
성능 최적화
- 읽기/쓰기 작업 분리로 부하 분산
- Connection Pooling을 통한 데이터베이스 연결 효율화
-
확장성
- 필요에 따라 Replica 노드 추가 가능
- 트래픽 증가에 유연하게 대응
마치며
이러한 구성을 통해 안정적이고 확장 가능한 PostgreSQL 환경을 구축할 수 있습니다. 실제 운영 환경에서는 모니터링과 백업 전략도 함께 고려해야 합니다.